[Algorithm] Sort Algorithm 2
in Computer Science on Algorithm
Sort Algorithm 정렬 알고리즘
Quick Sort 퀵 정렬
- 기준점(pivot)을 정해서 기준점보다 작은 데이터는 왼쪽(left), 큰 데이터는 오른쪽(right)로 모으는 방식
- 평균적으로 매우 빠른 수행 속도를 내는 정렬 방식
- 분할 정복 알고리즘의 하나로, 재귀 알고리즘을 이용한 정렬 방식
동작 원리
- n개의 데이터가 있는 리스트의 첫 번째 데이터를 피벗으로 설정
- 피벗을 기준으로 작은 값과 큰 값을 분류
- 만약 데이터가 피벗보다 작다면
left리스트에 데이터 추가 - 만약 데이터가 피벗보다 크다면
right리스트에 데이터 추가
- 만약 데이터가 피벗보다 작다면
- 리스트의 길이가 1 이하가 될 때 까지
left리스트와right리스트 함수 재귀
def quick_sort(data):
if len(data) <= 1:
return data
left, right = list(), list()
pivot = data[0]
for index in range(1, len(data)):
if pivot > data[index]:
left.append(data[index])
else:
right.append(data[index])
return quick_sort(left) + [pivot] + quick_sort(right)
이렇게 구현 된 퀵 정렬은 따로 left와 right 리스트의 메모리를 재귀 호출 될 때 마다 생성하여 리턴하기 때문에 메모리 사용 측면에서 비효율적
인덱스 접근을 이용하면 추가 메모리 사용이 적은 제자리 정렬의 퀵 정렬은 다음과 같이 구현 가능
동작 원리
- n개의 데이터가 있는 리스트의 가운데 데이터를 피벗으로 설정
- 두 인덱스가 서로 교차해서 지나칠 때까지 시작 인덱스(left)는 계속 증가시키고, 마지막 인덱스(right)는 계속 감소시키게 반복
left의 데이터가 피벗보다 더 작은 경우left값 증가를 반복 (피벗보다 큰데 좌측에 있는 값 탐색)right의 데이터가 피벗보다 더 클 경우right값 감소를 반복 (피벗보다 작은데 우측에 있는 값 탐색)
- 만약 두 인덱스가 아직 서로 교차해서 지나치지 않았다면
left의 값과right의 값을 교환 (잘못된 위치에 있는 두 값의 위치 교환) - 교환 후 다음 값을 가리키기 위해
left값 증가 및right값 감소 - 두 인덱스가 서로 교차하여 반복 종료 후 재귀 호출의 분할 기준점이 될
left리턴
def quick_sort(data):
def sort(left, right):
if right <= left:
return data
mid = partition(left, right)
sort(left, mid - 1)
sort(mid, right)
def partition(left, right):
pivot = data[(left + right) // 2]
while left <= right:
while data[left] < pivot:
left += 1
while data[right] > pivot:
right -= 1
if left <= right:
data[left], data[right] = data[right], data[left]
left, right = left + 1, right - 1
return left
return sort(0, len(data) - 1)
Merge Sort 병합 정렬
- 주어진 배열을 원소가 하나 밖에 남지 않을 때까지 계속 둘로 쪼갠 후에 다시 크기 순으로 재배열 하면서 원래 크기의 배열로 합치는 정렬 방식
- 퀵 정렬과 마찬가지로 분할 정복 알고리즘의 하나로, 재귀 알고리즘을 이용한 정렬 방식
동작 원리
- n개의 데이터가 있는 리스트의 가운데 값을
mid에 저장 mid를 기준으로left_data와right_data로 분할- 데이터의 길이가 2 이하가 될 때까지 재귀
left_data와right_data의 길이가L과R보다 커질 때 까지 반복- 만약
left_data가right_data보다 작을 경우left_data[L]을merged_data리스트에 삽입 후 L 증가 - 만약
left_data가right_data보다 클 경우right_data[R]을merged_data리스트에 삽입 후 R 증가
- 만약
merged_data에 나누어졌던 리스트가 크기를 비교하며 재귀 후 반복이 끝나면merged_data리턴
def merge_sort(data):
if len(data) < 2:
return data
mid = len(data) // 2
left_data = merge_sort(data[:mid])
right_data = merge_sort(data[mid:])
merged_data = list()
L, R = 0, 0
while L < len(left_data) and R < len(right_data):
if left_data[L] < right_data[R]:
merged_data.append(left_data[L])
L += 1
else:
merged_data.append(right_data[R])
R += 1
merged_data += left_data[L:]
merged_data += right_data[R:]
return merged_data
Heap Sort 힙 정렬
- 힙 자료구조를 활용하여 최댓값을 나열하는 정렬 방식
동작 원리
- 최대 힙에서 루트 노드는 최대값이므로 루트 노드 삭제 및
heap_data에 값 저장 - 힙 재구성
- 루트 노드 삭제 및 값 저장 반복 후
heap_data리턴
정렬 알고리즘 비교
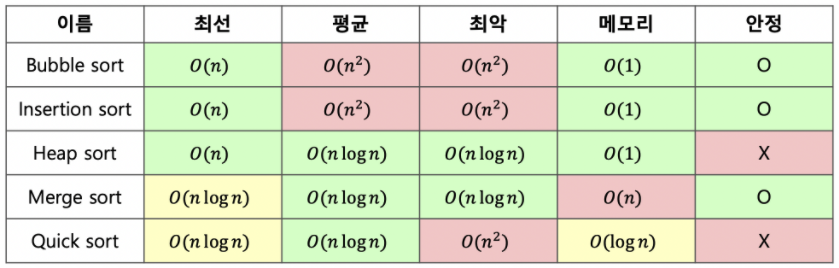
| 버블 정렬 | 선택 정렬 | 삽입 정렬 | 퀵 정렬 | 병합 정렬 | 힙 정렬 | |
|---|---|---|---|---|---|---|
| 정수 60,000개 기준 Runtime | 22.894s | 10.842s | 7.438s | 0.014s | 0.026s | 0.034s |
참고
잔재미코딩
신찬수 교수님 유튜브
위키 백과
Heee’s Development Blog
DaleSeo Blog
Naver D2
