[Algorithm] Minimum Spanning Tree
in Computer Science on Algorithm
Spanning Tree 신장 트리
- 원래의 그래프의 모든 노드가 연결되어 있으면서 트리의 속성을 만족하는 최소 연결 부분 그래프
- n개의 정점을 가지는 그래프의 최소 간선의 수는 (n-1)개이고, (n-1)개의 간선으로 연결되어 있으면 필연적으로 트리 형태가 됨
- 신장 트리의 조건
- 본래의 그래프의 모든 노드를 포함
- 모든 노드가 서로 연결
- 사이클이 존재하지 않음
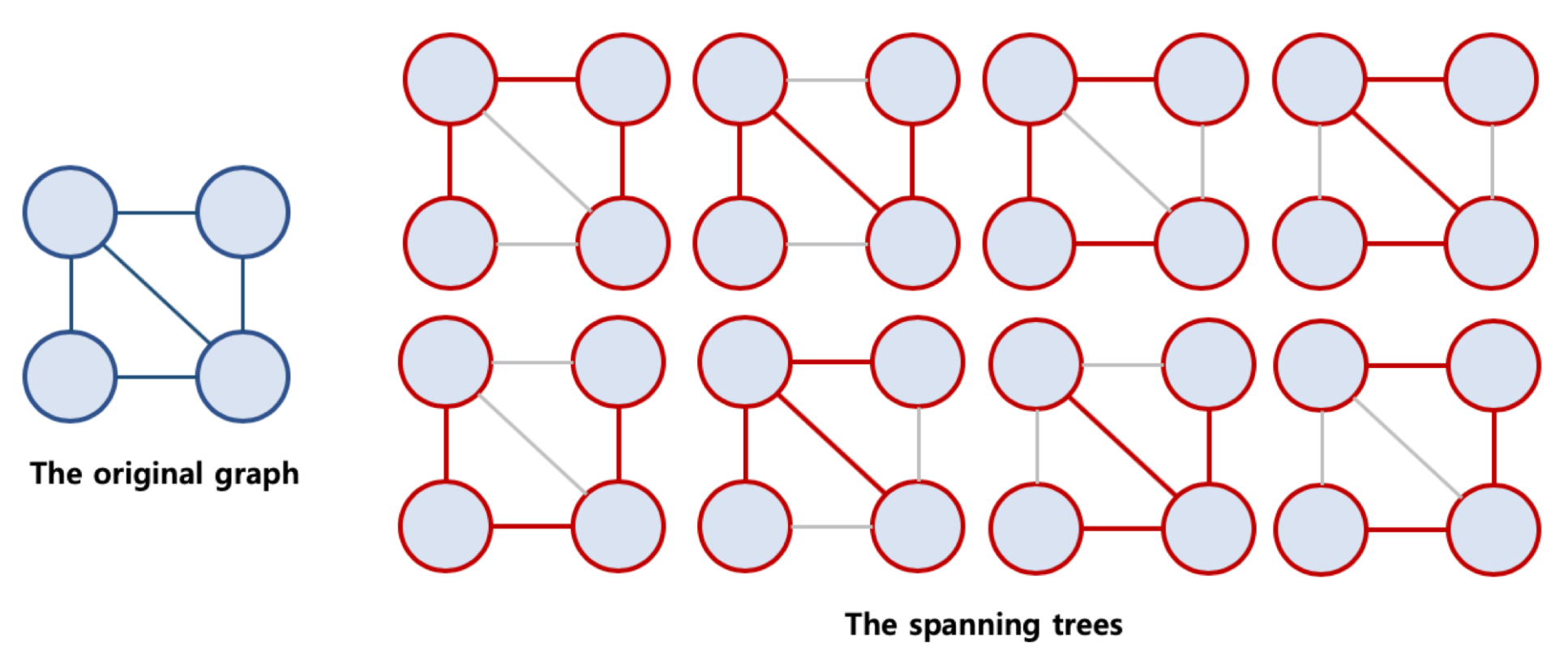
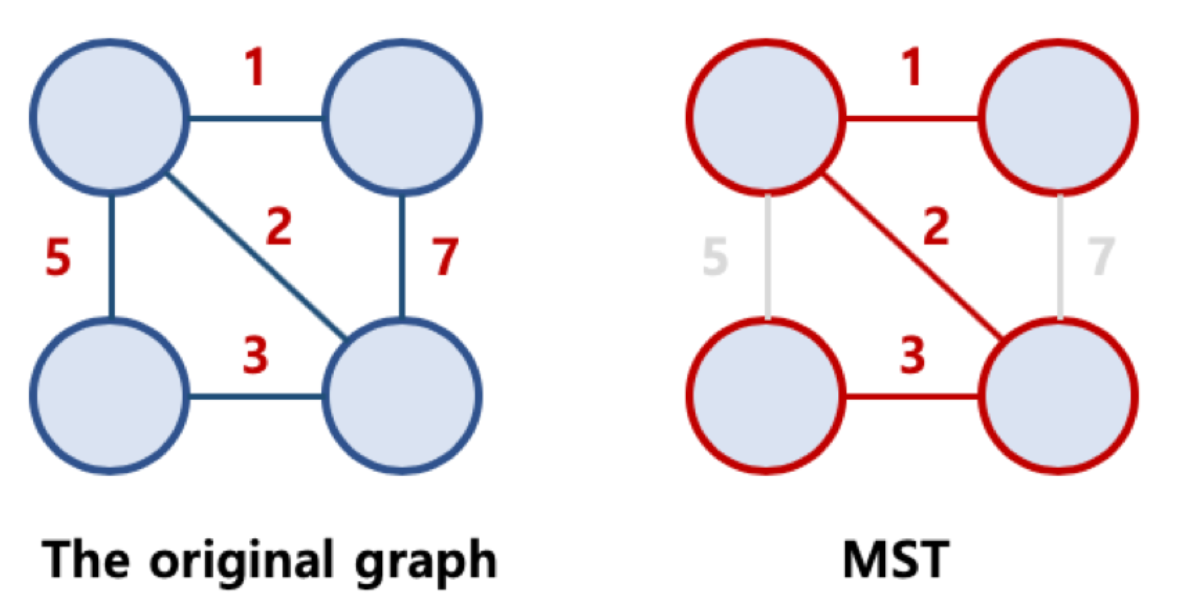
Minimum Spanning Tree 최소 신장 트리
- 가능한 Spanning Tree 중 간선의 가중치 합이 최소인 Spanning Tree
- 각 간선의 가중치가 동일하지 않을 때는 단순히 가장 적은 간선을 사용한다고 해서 최소 비용이 얻어지는 것은 아님
- 대표적인 최소 신장 트리의 사용 예시에는 통신망, 도로망, 유통망에서 길이, 구축 비용, 전송 시간 등을 최소로 구축하려는 경우 등이 있음
- 대표적인 최소 신장 트리 알고리즘에는 크루스칼 알고리즘과 프림 알고리즘이 있음
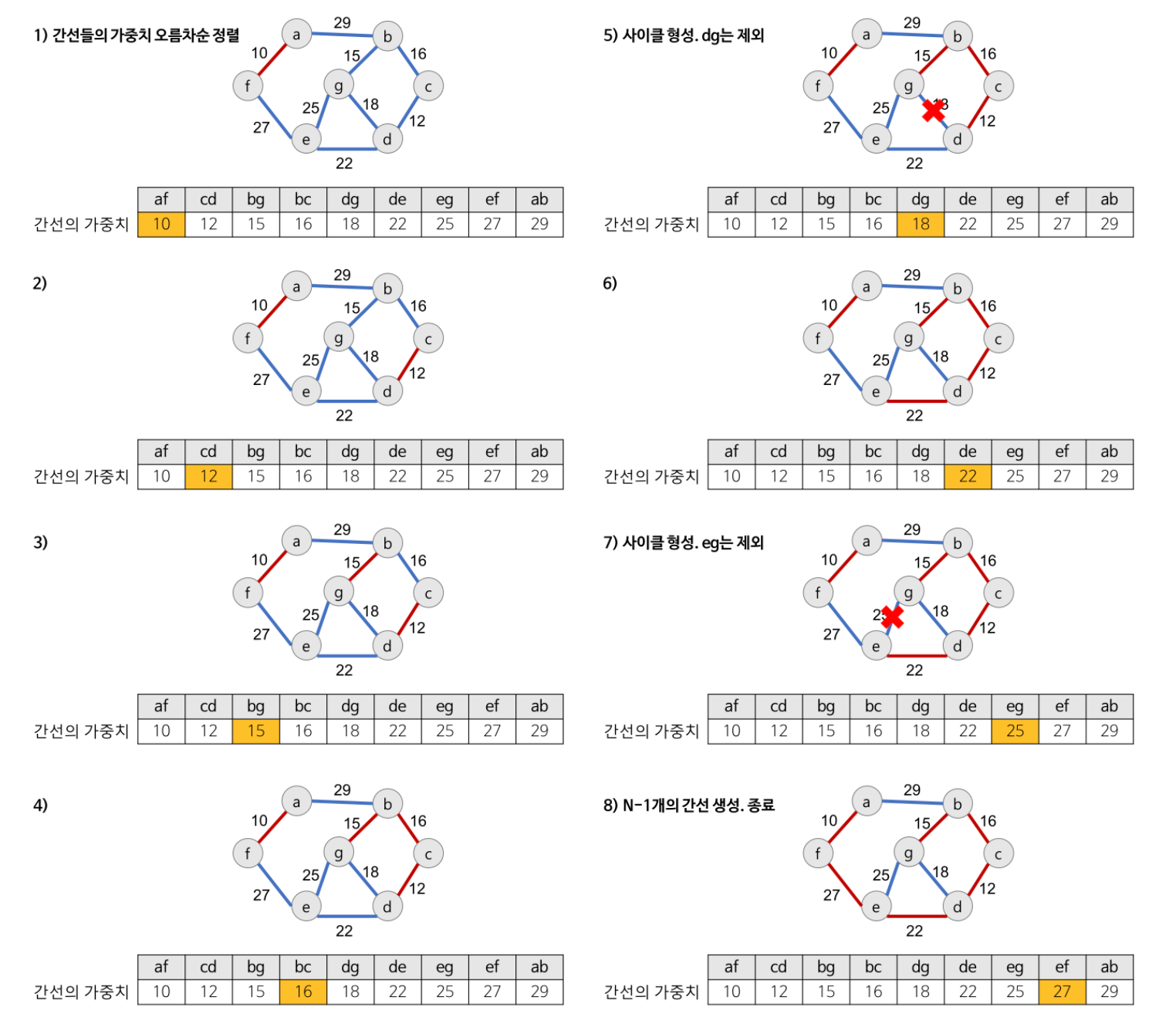
Kruskal’s algorithm 크루스칼 알고리즘
- 그리디 알고리즘을 기반으로 Union-Find 알고리즘을 활용하여 가중치 그래프의 모든 정점을 최소 비용으로 연결하는 최적 해답을 구하는 알고리즘
- 최소 비용 신장 트리가 최소 비용의 간선으로 구성된다는 점과 사이클을 포함하지 않는다는 조건에 근거하여 각 단계에서 사이클을 이루지 않는 최소 비용 간선을 선택
크루스칼 알고리즘 로직
- 모든 정점을 독립적인 집합으로 만듦
- 모든 간선을 가중치의 오름차순으로 정렬하고, 비용이 작은 간선부터 양 끝의 두 정점을 비교
- 사이클을 형성하는 간선을 제외하기 위해 두 정점의 최상위 정점을 확인하고, 서로 다를 경우 두 정점을 연결
- 사이클 생성 여부를 확인하기 위해 추가하고자 하는 간선의 양끝 정점이 같은 집합에 속해 있는지를 Union-Find 알고리즘을 통해 체크
- 모든 정점이 연결될 때 까지 2번 3번 반복
크루스칼 알고리즘 구현
mygraph = {
'vertices': ['A', 'B', 'C', 'D', 'E', 'F', 'G'],
'edges': [
(7, 'A', 'B'),
(5, 'A', 'D'),
(7, 'B', 'A'),
(8, 'B', 'C'),
(9, 'B', 'D'),
(7, 'B', 'E'),
(8, 'C', 'B'),
(5, 'C', 'E'),
(5, 'D', 'A'),
(9, 'D', 'B'),
(7, 'D', 'E'),
(6, 'D', 'F'),
(7, 'E', 'B'),
(5, 'E', 'C'),
(7, 'E', 'D'),
(8, 'E', 'F'),
(9, 'E', 'G'),
(6, 'F', 'D'),
(8, 'F', 'E'),
(11, 'F', 'G'),
(9, 'G', 'E'),
(11, 'G', 'F')
]
}
parent = dict()
rank = dict()
def find(node):
# path compression 기법
if parent[node] != node:
parent[node] = find(parent[node])
return parent[node]
def union(node_v, node_u):
root1 = find(node_v)
root2 = find(node_u)
# union-by-rank 기법
if rank[root1] > rank[root2]:
parent[root2] = root1
else:
parent[root1] = root2
if rank[root1] == rank[root2]:
rank[root2] += 1
def make_set(node):
parent[node] = node
rank[node] = 0
def kruskal(graph):
mst = list()
# 1. 초기화
for node in graph['vertices']:
make_set(node)
# 2. 간선 weight 기반 sorting
edges = graph['edges']
edges.sort()
# 3. 간선 연결 (사이클 없는)
for edge in edges:
weight, node_v, node_u = edge
if find(node_v) != find(node_u):
union(node_v, node_u)
mst.append(edge)
return mst
크루스칼 알고리즘 시간 복잡도
- 모든 정점을 독립적인 집합으로 만드는 데 걸리는 시간 복잡도 O(V)
- 모든 간선을 가중치의 오름차순으로 정렬하고, 비용이 작은 간선부터 양 끝의 두 정점을 비교하는 데 걸리는 시간 복잡도 O(ElogE)
- 팀소트(파이썬
sort함수의 표준 정렬 알고리즘)를 사용한다면 시간 복잡도는 O(nlogn) 이며, n은 간선을 나타냄
- 팀소트(파이썬
- 사이클을 형성하는 간선을 제외하기 위해 두 정점의 최상위 정점을 확인하고 두 정점을 연결하는 데 걸리는 시간 복잡도 O(1)
- union-by-rank 와 path compression 기법 사용시 시간 복잡도가 결국 상수값에 수렴함
- 이에 대한 자세한 내용은 여기참조
- O(V + ElogE + 1)에 대하여 최대 V^2 = E를 만족하기에 크루스칼 알고리즘은 O(ElogE)의 시간복잡도를 가짐
Prim’s Algorithm 프림 알고리즘
- 시작 정점을 선택한 후, 정점에 인접한 간선중 최소 간선으로 연결된 정점을 선택하고, 해당 정점에서 다시 최소 간선으로 연결된 정점을 선택하는 방식으로 최소 신장 트리를 확장해가는 방식
- 크루스칼 알고리즘과는 다르게 프림 알고리즘은 특정 정점에서 시작, 해당 정점에 연결된 가장 가중치가 작은 간선을 선택, 간선으로 연결된 정점들에 연결된 간선 중 가장 가중치가 작은 간선을 택하는 방식
프림 알고리즘 로직
- 모든 간선 정보를
adjacent_edges에 저장 - 임의의 정점을 선택 후 연결된 노드 집합
connected_nodes에 삽입 - 선택된 정점에 연결된 간선들을 간선 리스트
candidate_edge_list에 삽입 candidate_edge_list에서 최소 가중치를 가지는 간선부터 추출- 해당 간선에 연결된 인접 정점이
connected_nodes에 이미 들어 있다면 스킵 (사이클 방지) - 해당 간선에 연결된 인접 정점이
connected_nodes에 들어 있지 않으면 해당 간선을 선택하고 해당 간선 정보를mst에 삽입
- 해당 간선에 연결된 인접 정점이
mst에 정보가 삽입된 간선에 연결된 인접 정점의 간선들 중,connected_nodes에 없는 노드와 연결된 간선들만candidate_edge_list에 삽입connected_nodes에 있는 노드와 연결된 간선들을 간선 리스트에 삽입해도, 해당 간선은 스킵될 것이기 때문에 시간복잡도 최소화
- 선택되어
mst에 삽입 된 간선은candidate_edge_list에서 제거 candidate_edge_list에 더 이상의 간선이 없을 때까지 3, 4, 5, 6번 반복
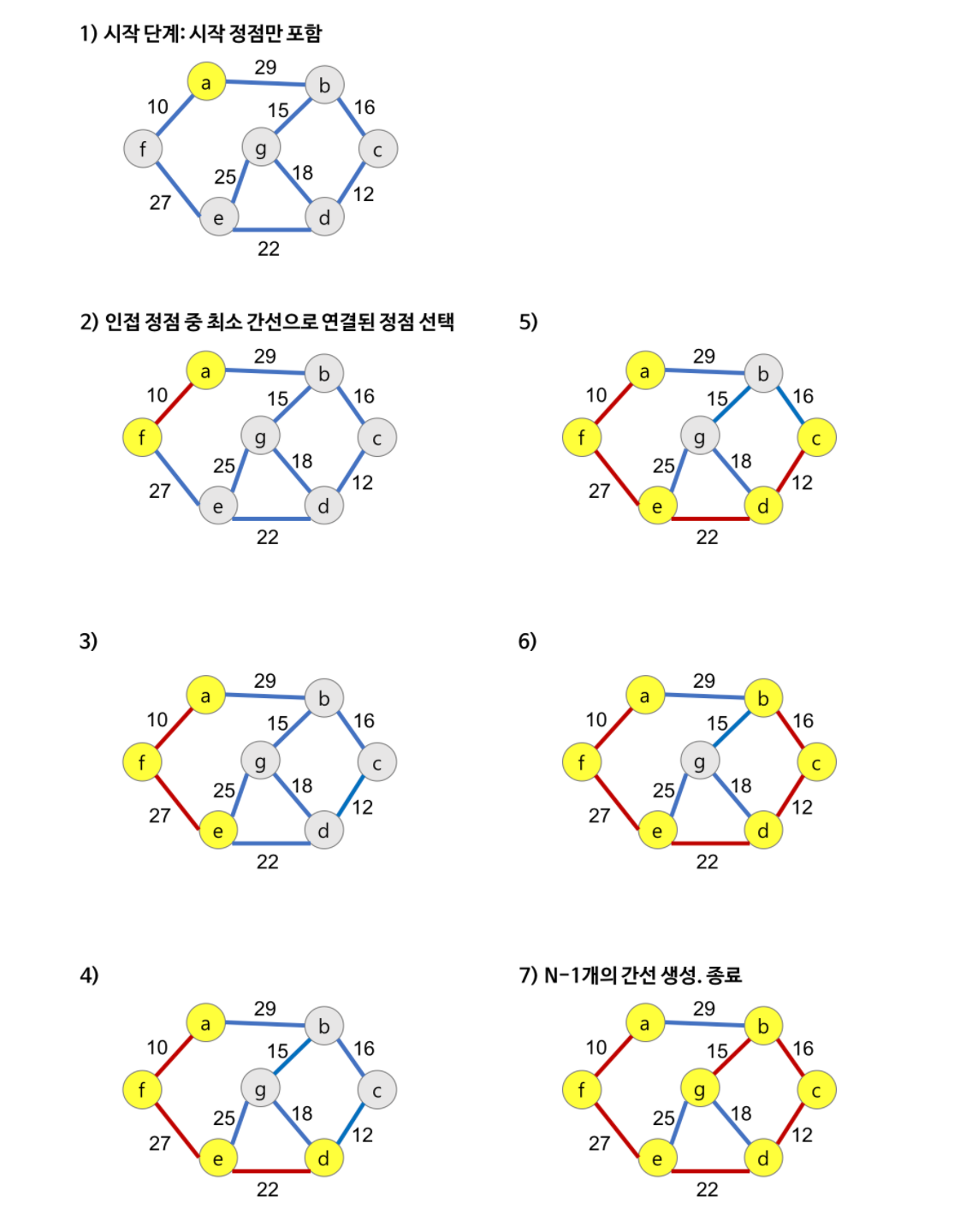
프림 알고리즘 구현
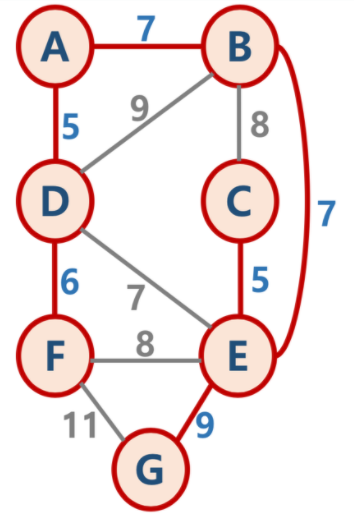
mygraph = {
'A': {'B': 7, 'D': 5},
'B': {'A': 7, 'D': 9, 'C': 8, 'E': 7},
'C': {'B': 8, 'E': 5},
'D': {'A': 5, 'B': 9, 'E': 7, 'F': 6},
'E': {'B': 7, 'C': 5, 'D': 7, 'F': 8, 'G': 9},
'F': {'D': 6, 'E': 8, 'G': 11},
'G': {'E': 9, 'F': 11}
}
from collections import defaultdict
from heapq import *
def prim(start_node, edges):
mst = list()
adjacent_edges = defaultdict(list)
for weight, n1, n2 in edges:
adjacent_edges[n1].append((weight, n1, n2))
adjacent_edges[n2].append((weight, n2, n1))
connected_nodes = set(start_node)
candidate_edge_list = adjacent_edges[start_node]
heapify(candidate_edge_list)
while candidate_edge_list:
weight, n1, n2 = heappop(candidate_edge_list)
if n2 not in connected_nodes:
connected_nodes.add(n2)
mst.append((weight, n1, n2))
for edge in adjacent_edges[n2]:
if edge[2] not in connected_nodes:
heappush(candidate_edge_list, edge)
return mst
defaultdict함수를 사용하여, key에 대한 value를 지정하지 않았을 때, 빈 리스트로 초기화 시킬 수 있게 함- 최소 힙을 활용하여
candidate_edge_list에서 최소 가중치를 추출함에 있어 O(nlogn)의 시간 복잡도를 가질 수 있게 함
프림 알고리즘 시간 복잡도
- 가장 클래식한 방법으로
candidate_edge_list에서 최소 가중치를 찾을 때 단순 정렬을 통해 찾는다면 시간 복잡도는 O(V^2) - 이 포스트에서는 최소 가중치를 찾을 때 최소 힙을 사용하여 보다 효율적으로 O(ElogE)의 시간 복잡도를 가짐
- 개선된 프림 알고리즘으로 간선이 아닌 노드 중심으로 우선순위 큐를 적용하면 O(ElogV)의 시간 복잡도로 보다 효율적인 코드 작성 가능
- 다만 이 포스트에서는 다루지 않으니 자세한 내용은 여기 참조
크루스칼 알고리즘 vs 프림 알고리즘
- 크루스칼 알고리즘은 간선 위주의 알고리즘, 프림 알고리즘은 정점 위주의 알고리즘
- 크루스칼 알고리즘은 시작점을 따로 정하지 않고 최소 비용의 간선을 차례로 대입하면서 MST를 구성하기 때문에 항상 사이클을 확인해야 하는 반면 프림 알고리즘은 시작점을 정하고 시작점에서 가까운 정점을 선택하면서 MST를 구성하기 때문에 사이클을 이루지 않음
- 크루스칼 알고리즘은 간선을 기준으로 정렬하는 과정이, 프림 알고리즘은 최소 거리의 정점을 찾는 과정이 시간복잡도를 결정
- 간선의 개수가 적은 경우에는 크루스칼 알고리즘이, 간선의 개수가 많은 경우에는 프림 알고리즘이 유리
참고
잔재미코딩
신찬수 교수님 유튜브
Heee’s Development Blog
